Deep Learning
Can a CNN tell the difference between fake galaxies (that I inject into real imaging data) and real ones?
Table of Contents
Background¶
I am getting my PhD in astrophysics from UC Berkeley. My research focuses on observational cosmology, which boils down to analyzing images of the night sky. I help develop a pipeline that automatically detects stars and galaxies in multi-wavelength images and fits models to them. From the sample of galaxies we collect, it is possible to answer questions like, “how has the expansion rate of the Universe changed over time?”. The Sloan Digital Sky Survey (SDSS) showed that you can do this with a large enough sample (about a million galaxies) and region of the sky (1/3 of it). My team is carrying out the Legacy Survey to detect 30x more, and up to 6x fainter, galaxies than SDSS. The most distant galaxies are about 10 billion lightyears away.
Our goal is to create a 2D map of the positions of about 30 million galaxies extracted from more than 100 TBs of images. Given the locations, we can take a spectrum of each galaxy (e.g. how bright it is at many wavelengths of visible light) and infer how far away it is. From this 3D map we can measure the expansion rate of the Universe at different points in time (Eisenstein & Hu 1998; Eisenstein et al. 2005; Seo & Eisenstein 2007; Butler et al. 2017).
The primary goal of my thesis is to measure the statistical bias and variance of our pipeline. How does our completeness depend on whether a galaxy is bright or faint, blue or red, big or small? How well does our pipeline handle image artifacts, instrument issues, or transient objects?
To answer all of this, John Moustakas, a professor at Siena College, and I developed the obiwan code. It does Monte Carlo simulations of the pipeline by adding fake galaxies to random locations in the images, running the pipeline, and repeating.
The success of all this depends on whether or not the fake galaxies are representative of the true galaxy population. If not, we are measuring the bias and variance of a sample that does not exist in the data. I need to show that the fake galaxies “look” like the real ones. Enter the Convolutional Neural Network (CNN)…
The Problem¶
This is a supervised binary classification problem of labeled multi-wavelength images. The training set is huge, at least 60 million examples, and each example is six images (64 x 64 x 6 pixels). There is one image for each of the three wavelength bands and another three images to encode camera artifacts and the variance of each pixel.
The CNN predicts whether a galaxy is fake (1) or real (0).
Novel¶
This project is novel because half the training images are model-generated and the goal is for the CNN to do poorly. If the CNN cannot do better than guessing the most numerous class, then the fake galaxies “look like” real ones. i.e. my model is representative of reality. This has generated interest in the team since a similar CNN could be trained using models of other types of galaxies.
Examples of Training Data¶
The galaxies below are some of the brightest in the training set (99th percentile in brightness). More Examples of fainter galaxies (75th, 50th, 25th, and 1st percentiles in brightness) are at the end.

Figure 1. The label for each image is on the left (R for Real and F for Fake) and its corresponding g-band magnitude is the number on the right (the smaller the number, the brighter the galaxy). Each row represents a single galaxy imaged at three different wavelengths. The color-image (left most panel) shows the colors you would see by eye, while the black and white-images (right six panels) are the training data: three images for the g, r, and z-bands and their corresponding artifact/inverse variance (ivar) images. Consecutive rows of R and F (rows 1 and 2, 3 and 4, etc.) have similar g-band magnitudes so that a fair comparison can be made.
The examples reveal at least two challenges for the CNN.
- Only the central-object matters, but there are many off-center objects in the images. These are random background sources, often bright galaxies or stars that we are not interested in.
- These galaxies are very faint. The CNN must be able to dig out the low Signal to Noise sources.
CNN Architecture¶
As a starting point, I used TensorFlow to build a CNN similar to LeNet-5 with the following architecture:
| Layer | Feature Maps | Size | Kernel Size | Stride | Activation Function |
|---|---|---|---|---|---|
| Input Image | 6 | 64x64 | |||
| Convolution | 18 | 64x64 | 7x7 | 1 | ReLU |
| Avg. Pooling | 18 | 32x32 | 7x7 | 2 | ReLU |
| Convolution | 36 | 32x32 | 7x7 | 1 | ReLU |
| Avg. Pooling | 36 | 16x16 | 7x7 | 2 | ReLU |
| Convolution | 54 | 16x16 | 7x7 | 1 | ReLU |
| Avg. Pooling | 54 | 8x8 | 7x7 | 2 | ReLU |
| Fully Connected | 64 | ReLU | |||
| Fully Connected | 2 | Softmax |
The input image has 64 x 64 x 6 pixels. The CNN is much shallower than the ImageNet ILSVRC winners, so in addition to tuning the number of feature maps, kernel size, stride, etc., I plan to make it deeper.
Intel Xeon Phi¶
I have used the Cray XC30 (Edison) and Cray XC40 (Cori) supercomputers at the National Energy Research Scientific Computing Center (NERSC) for the majority of my thesis work. With almost 10,000 Intel Xeon Phi processor nodes on Cori, NERSC Staff are particularly interested in helping users run on Xeon Phi.
I decided to train on Xeon Phi, instead of a GPU, when NERSC/Intel released optimized installs of many of the popular machine learning libraries (Caffe, TensorFlow, Theano, Torch, see full list). I created an initial training set of 2048 images with an equal number of fake and real galaxies. The images are float32 so I stored every 512 examples in a file, thinking that a 50 MB file would fit in memory on most machines.
It takes about 3 minutes to train 4 epochs of 2048 images on a single Xeon Phi node (68 hardware cores). For hundreds of nodes, I plan on training a different minibatch with each MPI task, updating a global set of weights using the learned weights from the minibatches, then repeating. Although multi-node support is not yet available to users, NERSC Staff can scale ResNet-50 and DCGAN to 1024 Xeon Phi nodes.
Fortunately, I hope to begin multi-node training soon as the NERSC Staff have volunteered my CNN for non-benchmark multi-node testing.
TensorBoard & Profiling¶
The accuracy, loss, and graph from the 4 training epochs are shown below using TensorBoard. Different colors correspond to me restarting the training twice to demonstrate that the checkpoints are working.
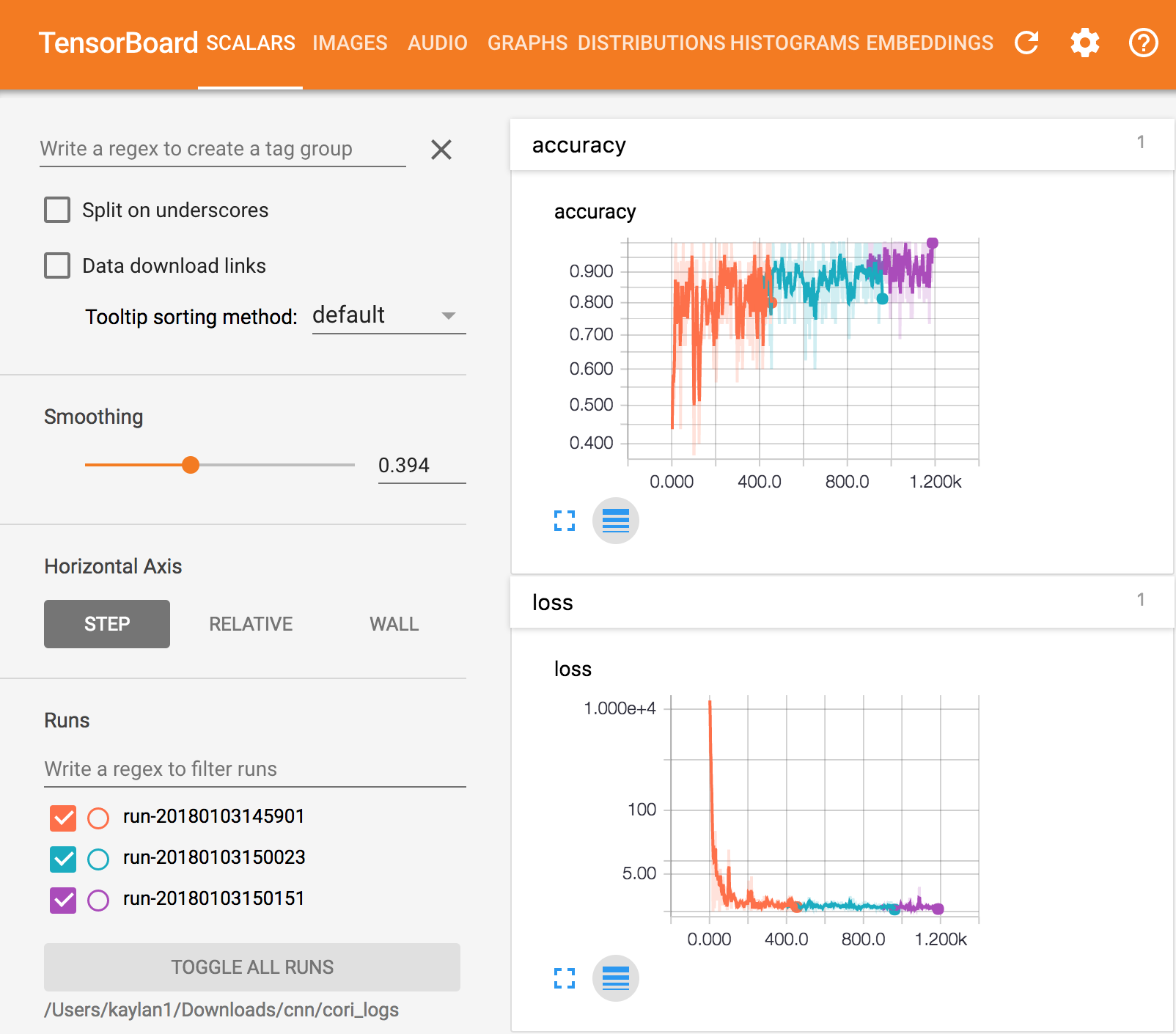
Figure 2. Accuracy and loss with TensorBoard
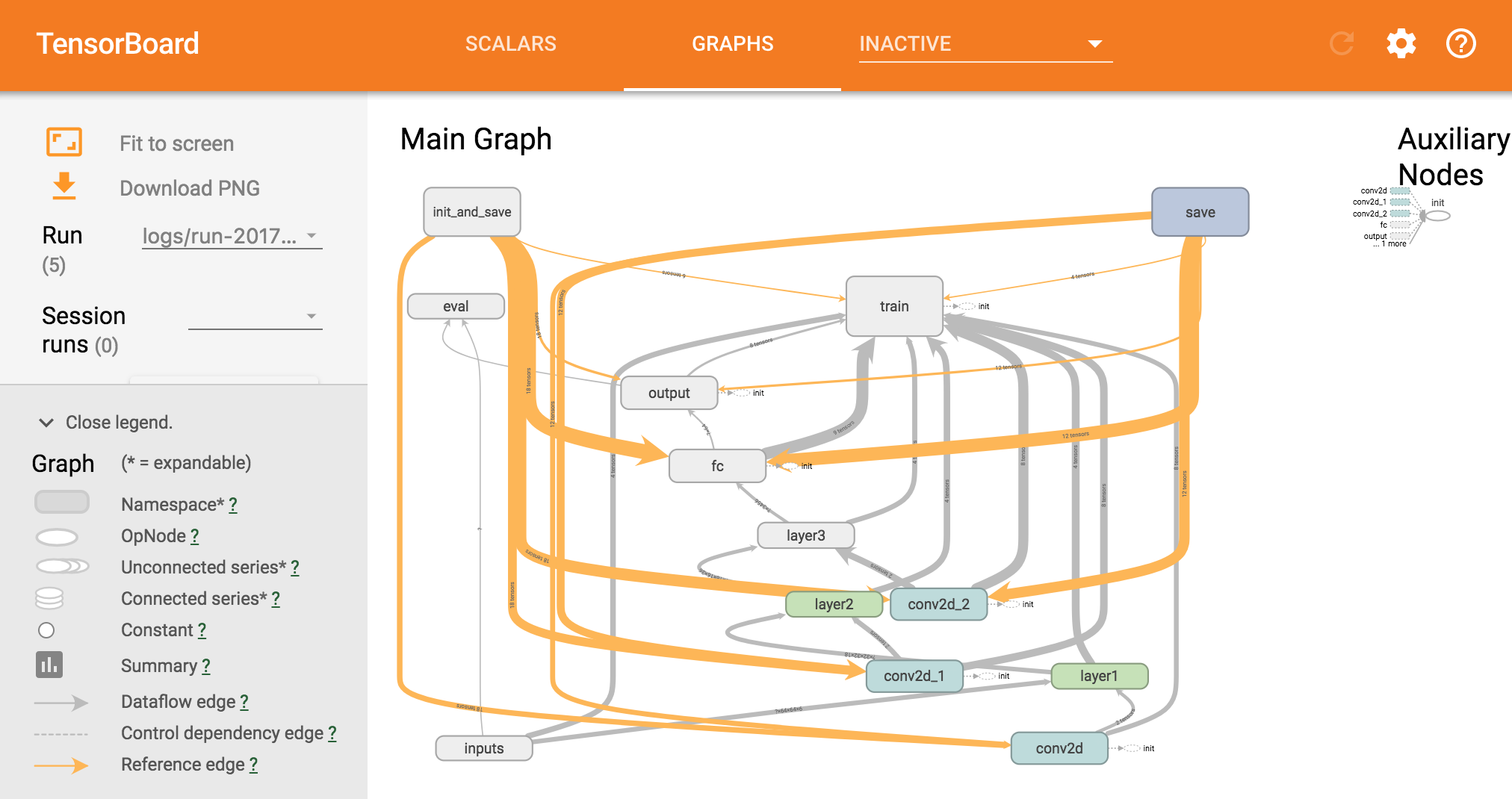
Figure 3. Graph with TensorBoard
I also profile my CNN using TensorFlow’s timeline object. This writes timings for each node of the graph to a json file. You can inspect it with Google Chrome, by going to chrome://tracing and clicking load. Here’s what it looks like.
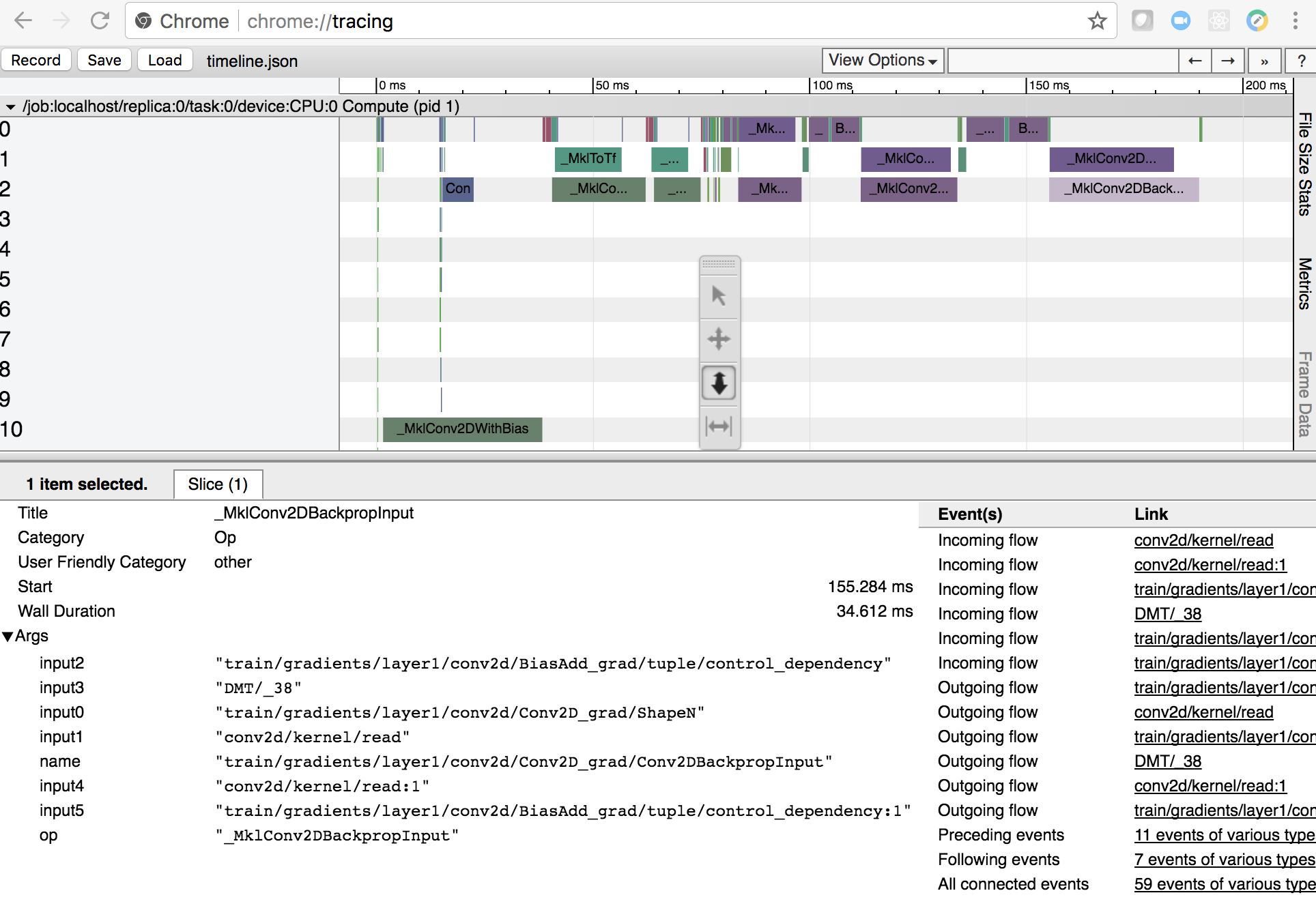
Figure 4. Profiling with TensorFlow’s timeline and Google Chrome
Instructions¶
See the following for training the CNN at NERSC.
Create Training Set¶
obiwan.dplearn.create_training(source code: create_training.py) saves 64x64 pixels cutouts of each source to an HDF5 file, indexed by its unique tractor id. This writes one HDF5 file per brick for Data Releases, or one file per obiwan Monte Carlo simulation.
Fake galaxies are designed to occupy the narrow region of parameter space we are interested in, but real galaxies do not. When building the real galaxy training set, real galaxies outside this parameter space are removed.
There are millions of fake and real galaxy images, so I use mpi4py to scale to a few hundred compute nodes. About 1 million real galaxy examples can be created in an hour using 50 nodes. Use the following SLURM script:
#SBATCH -p regular
#SBATCH -N 50
#SBATCH -t 01:00:00
#SBATCH --account=desi
#SBATCH -J train
#SBATCH -L SCRATCH,project
#SBATCH -C haswell
let tasks=32*${SLURM_JOB_NUM_NODES}
# NERSC / Cray / Cori / Cori KNL things
export KMP_AFFINITY=disabled
export MPICH_GNI_FORK_MODE=FULLCOPY
export MKL_NUM_THREADS=1
export OMP_NUM_THREADS=1
srun -n ${tasks} -c 1 python create_training.py \
--which tractor --bricks_fn bricks.txt --nproc ${tasks}
--savedir /global/cscratch1/sd/kaylanb/obiwan_out/dr5_hdf5
For fake galaxies, replace –which tractor with –which sim. The resulting HDF5 files are on at NERSC:
- real from DR5: /global/cscratch1/sd/kaylanb/obiwan_out/dr5_hdf5
- fake from Obiwan using DR5: /global/cscratch1/sd/kaylanb/obiwan_out/elg_dr5_coadds/hdf5
Split Train/Test¶
obiwan.dplearn.split_testtrain(source code: split_testtrain.py) randomly shuffles the real and fake galaxies in the above HDF5 files, splits this into 80% training and 20% test, then repackages the examples in numpy binary files.
Use the same SLURM job as above, but with:
srun -n ${tasks} -c 1 python split_testtrain.py \
--bricks_fn bricks.txt --nproc ${tasks} \
--real_dir /global/cscratch1/sd/kaylanb/obiwan_out/dr5_hdf5 \
--sim_dir /global/cscratch1/sd/kaylanb/obiwan_out/elg_dr5_coadds \
--save_dir /global/cscratch1/sd/kaylanb/obiwan_out/dr5_testtrain
The resulting numpy files are on at NERSC: * /global/cscratch1/sd/kaylanb/obiwan_out/dr5_testtrain
The training data are named [xy]train_[0-9]+.npy and have 512 64x64x6 examples per file. The test data are named [xy]test_[0-9]+.npy.
Train¶
obiwan.dplearn.cnn(source code: cnn.py) trains the CNN using TensorFlow. The following runs on a single Xeon Phi node using 68 threads (“srun” is not needed because this is a single node job):#!/bin/bash #SBATCH -N 1 #SBATCH -C knl,quad,cache #SBATCH -p debug #SBATCH -J tf #SBATCH -t 00:30:00 module load tensorflow/intel-head export OMP_NUM_THREADS=68 export KMP_AFFINITY="granularity=fine,verbose,compact,1,0" export KMP_SETTINGS=1 export KMP_BLOCKTIME=1 export isKNL=yes python cnn.py --outdir /global/cscratch1/sd/kaylanb/obiwan_out/cnn
This will write three sets of metadata:
- checkpoints: /global/cscratch1/sd/kaylanb/obiwan_out/cnn/ckpts
- tensorboard logs: /global/cscratch1/sd/kaylanb/obiwan_out/cnn/logs
- profiling: /global/cscratch1/sd/kaylanb/obiwan_out/cnn/prof
The CNN will restart from the most recent checkpoint file, if any exist.
More Examples¶
Galaxies with 75th perentile in brightness:

Galaxies with 50th perentile in brightness:

Galaxies with 25th perentile in brightness:

Galaxies with 1st percentile in brightness (faintest in the training set):
